Architecting enterprise AI agents


Bridging probablistic search with deterministic knowledge graphs
When we set out to architect a custom consultative AI agent for a recent enterprise project, we knew we needed a system capable of answering complex, highly technical questions with absolute accuracy. We needed an intelligent assistant that didn't just guess at answers, but truly understood the strict intricacies of a massive product ecosystem.
Our first instinct was to test standard Retrieval-Augmented Generation (RAG). Like many AI engineering teams, we spun up a vector database, chunked our documentation, and wired it up to an AI Agent. For basic queries, it worked. But as we pushed the system with real-world, nuanced questions, we quickly found it lacking.
Standard RAG is inherently probabilistic; it relies on semantic similarity to fetch text chunks. When dealing with dense technical documentation, fetching an isolated paragraph often strips away the context the Agent needs to reason correctly. This is the root cause of many LLMs' hallucinations.
The pivot: From "magic" agents to state-machine orchestration
The industry often promotes "autonomous agents" as managed black boxes. You hand them a prompt, and they run in a hidden, internal loop. If an autonomous agent hallucinates a tool call, enters an infinite loop, or provides a technically incorrect answer, you have no way to intercept the logic or audit why it made that decision.
In our experience, black boxes are a liability for "Day 2" operations (what happens after a system goes live in production). Instead, we built our own transparent, state machine-based orchestration using the LangGraph framework.
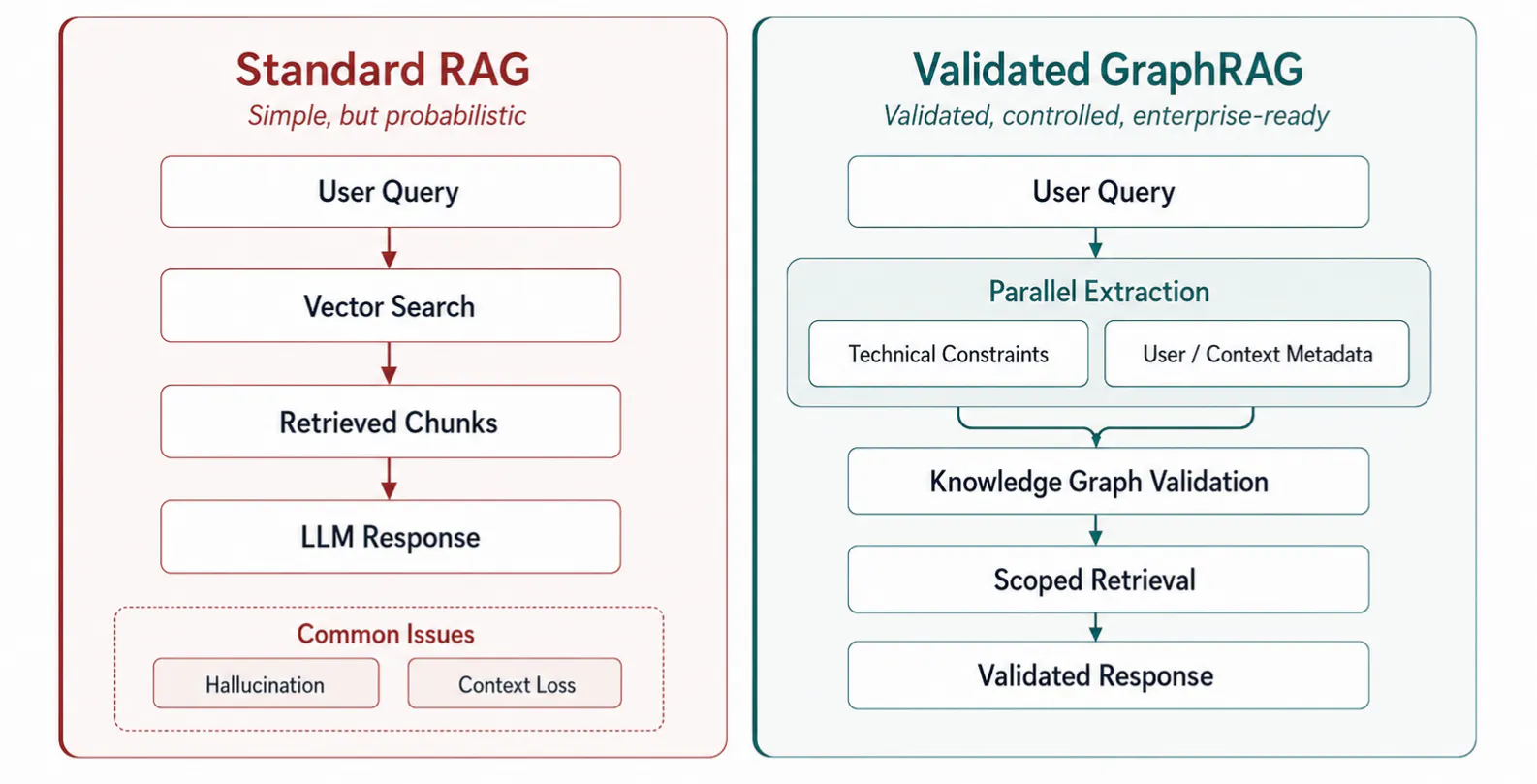
Diagram: Standard RAG vs. Validated GraphRAG
By defining the conversation as a series of controlled nodes, we replaced unpredictable autonomy with architectural rigor. The system doesn't just "guess" what to do next; it is governed by a clear, step-by-step process, which ensures that all user interactions move in one direction and are processed through specific logic gates.
1. Parallel intent extraction
In our orchestration logic, we don't process user input linearly. When a user describes their requirements, the system calls multiple Data Agents to extract technical constraints and user metadata in parallel.
While the system identifies the specific requirements, it simultaneously structures the broader contextual data. This concurrency reduces latency and ensures that the technical and environmental contexts are captured with equal fidelity from the very first message.
2. Standardizing the fuzzy middle
The biggest challenge in GraphRAG is mapping messy human language to a rigid database schema. We solved this with a Deterministic Fuzzy Match layer. Before querying the Knowledge Graph, the system runs a standardization step that maps natural language phrases to specific, validated taxonomy nodes. This bridges the gap between the probabilistic nature of LLMs and the deterministic requirements of a graph query.
3. Metadata-scoped retrieval
Rather than letting a vector search run wild across an entire documentation library, we use the Knowledge Graph as a high-precision filter. The Graph identifies the "deterministic candidates", like components or solutions that actually fit the user's constraints.
We then use these identifiers as metadata "pointers" to scope the vector retrieval. This ensures that the context injected into the prompt is pre-validated by business rules. We aren't asking the Narrative Agent to find the right solution; we are providing it with the validated options and asking it to explain the technical rationale based on the documentation.
4. Allowlist-validated synthesis
To eliminate the risk of our Agent recommending a non-existent or incompatible solution, we implemented a two-phase synthesis:
- Phase 1: The Agent is constrained to select valid identifiers from a system-provided allowlist generated by the Knowledge Graph.
- Phase 2: Only once the identifiers are locked in does the Agent generate the natural language response.
Day 2 operations: Observability with LangFuse
You cannot manage what you cannot see. For an enterprise-ready solution, we integrated LangFuse into the backend trace store. Every step of the orchestration, every parallel extraction, graph query, and synthesis phase, is captured as a structured trace.
This provides several critical "Day 2" advantages:
- Traceability: If a recommendation feels "off," we can look at the trace to see if the error happened during constraint extraction, the graph lookup, or the final synthesis.
- Session Reconstruction: We track the evolution of the technical context over time, allowing us to see exactly when a user's intent shifted or where a technical requirement became a bottleneck.
- Cost & Latency Auditing: We monitor token usage and execution time per node. This allows us to optimize prompts and graph queries for production scale without flying blind.
The technical stack
- Orchestration: LangGraph.js (State-machine logic)
- Knowledge Graph: Neo4j (Deterministic business rules)
- Models via Amazon Bedrock:
- Data Agent Model: Amazon Nova 2 Lite
- Narrative Agent Model: Claude Haiku 4.5
- RAG: Amazon Bedrock Knowledge Bases
- Vector Database: S3 Vectors
- Observability: LangFuse (Full-stack tracing and analytics)
Key takeaways for enterprise leaders
- Ditch the Black Box: Use state-machines for predictable, auditable AI behavior.
- Standardize First: Don't let Agents query your database directly; use a standardization layer to map "fuzzy" intent to "fixed" data.
- Validate at the Edge: Use allowlists during the synthesis phase to kill hallucinations before they reach the user.
- Instrument Everything: Observability tools turn "vibe-based" development into an empirical engineering discipline.
The ultimate goal of an enterprise AI solution is to bring clarity and efficiency, not to introduce a new layer of chaotic maintenance. By moving away from managed "magic" and prioritizing a transparent, engineer-driven architecture, we deliver a system built for "Day 2" operations: highly observable, secure, and predictably scalable.
This journey taught us that you can't just throw standard vector search at a complex enterprise problem. By providing our Agents with the right architecture to leverage both probabilistic retrieval and deterministic graphs, we are building AI systems that businesses can actually trust.
Is your organization hitting the limits of standard RAG? If you are struggling with hallucinations, complex data relationships, or fragile AI agent frameworks, you need an engineer-first approach to architecture. Reach out to our team to learn how we build robust, hybrid GenAI solutions tailored to your specific business rules.

